Quantitative finance and machine learning researcher focused on statistical modeling of financial markets, efficient transformer architectures, and loss-landscape-based knowledge distillation. Aspiring deep learning researcher working towards mastery in the field.
Education
B.S. Computer Science, Mathematics Minor, Machine Learning ConcentrationCarnegie Mellon University
May 2028
Pittsburgh, PA
Clubs: Quant Club (Goldman Sachs Quantathon: 100%), CMU Racing (built CUDA SVMs with 2x speedup for GPU midline generation).
Systems Work: Built Malloc (dynamic memory allocator) and a fully concurrent, thread-safe file system in C from scratch.
Gifted ProgramThe Woodlands Secondary School
Sep. 2020 – Jun. 2024
Selected Coursework
Machine Learning & Systems:
10-723 Generative AI (Ph.D.), 11-785 Deep Learning (Ph.D.), 10-701 Machine Learning (Ph.D.), 15-442 Machine Learning Systems (GPU + Kernel Optimization), 15-210 Parallel Computing + Algorithms, 15-213 Introduction to Computer Systems, 15-122 Data Structures and Algorithms, 15-150 Functional Programming
Math, Theory & Quantitative:
15-259 Probability and Computing, 21-270 Mathematical Finance, 15-251 Theoretical Computer Science/Discrete Math, 15-195 Competitive Programming, 21-241 Matrices and Linear Algebra, 21-295 Putnam Seminar
Research & Experience
Research-heavy ML work and production systems engineering across long-context modeling, diagnostics, and high-reliability infrastructure.
Software Development Engineer InternAmazon Web Services (AWS), Amazon DCV Team
May 2026 – Aug. 2026
Seattle, WA
Designed a Poisson-process packet-loss probe scheduler with provable guarantees, modeling inter-arrivals and anomaly recurrences to achieve at least 95% detection within seven recurrences; bounded heavy-tail wait behavior via Chernoff-bound analysis and Lambert W-based calibration.
Built a real-time C#/.NET diagnostics client (STA/MTA multithreading, async probes, rotating ndjson sessions) streaming 51 live metrics with embedded Gaussian fitting, pairwise correlation heatmaps, scatter/histograms, and session replay; reduced production troubleshooting time by roughly 50% for clients including Ferrari, Intuit, Netflix, and Volkswagen.
Architected an end-to-end time-series ML pipeline that injects CPU/GPU/RTT faults, dynamically labels causal signals, and fine-tunes a Tiny Time Mixer with custom anomaly-detection and forecasting heads; implemented root-cause routing for targeted remediation.
Machine Learning Summer Research InternGoomba Lab (Mamba Architecture), CMU
May 2025 – Aug. 2025
Pittsburgh, PA
Implemented a novel skip-connection-based Mamba model to mitigate multi-head-attention-related retrieval decline in SSM architectures for linear-time LLM settings.
Analyzed State Space Models and Mamba-2 gather-and-aggregate bottlenecks on MMLU retrieval benchmarks, including embedding perturbation/projection behavior.
Machine Learning Research InternCMU, Dr. David Touretzky
Jul. 2023 – Aug. 2024
Pittsburgh, PA
Engineered and deployed a React web application for simulating and visualizing textual Markov Chain models for 900+ professionals; used in a Concord University study (demo).
Built efficient graph generation and probabilistic next-word computation pipelines for bigram, trigram, and tetragram models with dynamic rendering/caching for low latency on large corpora.
Devised a loss-landscape distillation compression method (SPRKD) yielding 2-24% higher accuracy at roughly 10% of conventional training time in tested configurations.
Computed high-descent-potential saddle points in the teacher optimization landscape via Hessian approximation and spectral analysis for rapid curvature-tracking student convergence.
Engineered the company’s first ML backend infrastructure for high server volume and minimum latency using prompt chunking, custom drug vector embeddings, and safety guardrails.
Developed an LLM-based drug monograph summarization API and web application for real-time clinical patient diagnosis workflows.
Led a team of three to architect and deploy a recommendation engine API serving 45,000+ clients in prototyping, targeting maximal average rating-change uplift.
Built a hybrid GAN/Gradient Boosted Tree/MLP model pipeline and production deployment stack with Python, PyTorch, TensorFlow, XGBoost, SQL, and Flask.
Honors and Awards
Selected recognitions across quantitative trading, machine learning research, and international science competitions.
Optiver Market Making Competition
1st Place in Quantitative Trading; first freshman team to ever win.
Hudson River Trading, Best Use of Quantitative Data Award
Awarded for a machine-learning insurance-pricing platform.
U.S. National Security Agency (NSA)
Second Award in Cybersecurity/Mathematics at Regeneron ISEF (1600+ finalists) for neural network compression research.
Regeneron ISEF
One of 8 selected to represent Canada; Fourth Award in Robotics and Intelligent Machines.
Google DeepMind Offer
Selected as a research contractor as a sophomore (declined due to start date conflict).
TEDx Speaker, Innovire Speaker
Mathematical Foundations of ML and AI research talks (linktr.ee/AdiCMU).
Morgan Stanley / Quantbot Trading Competition
Highest Sharpe ratio across all submissions (6th overall).
Projects
Selected technical projects spanning efficient attention, optimization, and applied ML systems.
Featured
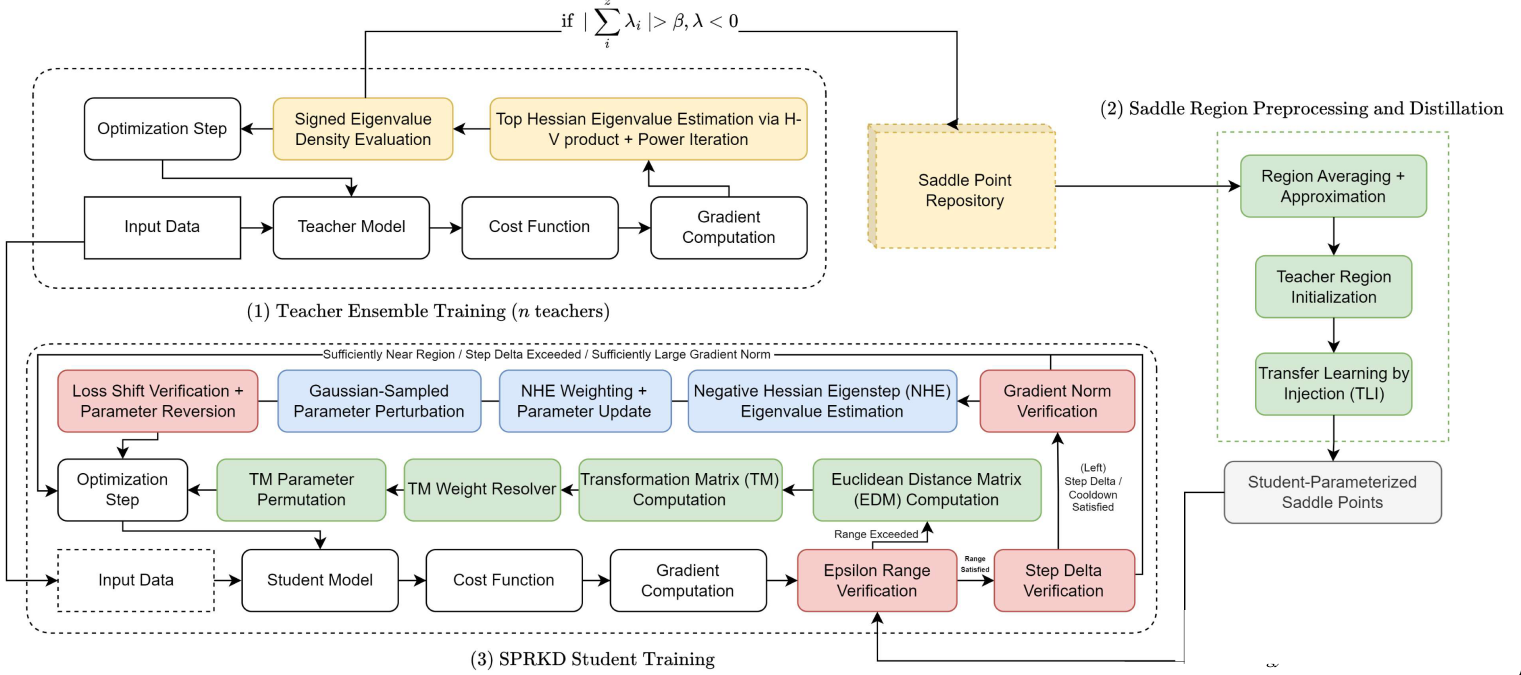
SPRKD (Saddle Point Recruitment for Knowledge Distillation)
2022-2026 | arXiv:2607.23346
Reframes knowledge distillation from teacher replication to curvature transfer, using teacher saddle regions as proxies for loss-landscape structure. Distilling from a weak 2-epoch teacher, SPRKD reaches 94.80% validation accuracy on malaria blood smear classification, outperforming Response KD by 24.70 points (70.10%) and matching scratch-trained controls to statistical equivalence. Hessian spectral analysis shows convergence to substantially flatter minima (trace 33.39 vs. 408.27 for RKD). Recognized by the NSA, ISEF, and WAICY.
The three-phase SPRKD pipeline: (1) teacher ensemble training with Hessian-based saddle tracking, (2) saddle region approximation and transfer by injection, (3) student training via decaying transformation matrices and negative Hessian eigensteps.
HFOLD: Dynamic Hidden State Heap Folding for Efficient Long-Context Attention
Introduced an inference-time memory mechanism that augments sliding-window attention with a bounded heap of high-relevance historical states. At each timestep, HFOLD retrieves top-ranked hidden states, reinserts transformed high-attention tokens, and applies a relevance-conditioned FOLD update (via GEM + RSM modules) to preserve information from evicted states. On Pythia 14M/31M evaluation, HFOLD recovered substantial long-range quality lost by plain sliding-window attention in language modeling (perplexity reduction from 225.1 to 91.7 in the full-attention-finetuned setting), while maintaining linear-time asymptotic behavior. The main current limitation is systems-level throughput overhead from non-fused heap operations.
Expected Gradient Divergence Weighting (EGDW) for TITANS Memory Updates
2025
Proposed a probabilistic memory-update rule for TITANS using Markov/Jensen bounds to stabilize neural memory writes; achieved improved validation cross-entropy relative to baseline despite higher train loss, indicating stronger generalization.
AI Education for the Next Generation: Nurturing K-12 Students
Aditya Dewan, Shanshan Jin, et al. Effective Methods for Teaching Large Language Models (LLMs) to Young Learners. Published on Amazon; peaked at #4 in Neural Networks.